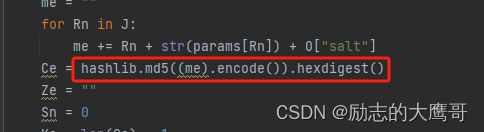
欢迎关注GZH《光场视觉》
摘要:在基于光场的一系列应用中,目标的三维重建是基础且关键的任务。普通光场只能重建单一视角而无法重建全景,并且在纹理特征匮乏的区域也无法生成准确的三维信息。针对以上问题,提出一种基于多视点编码光场的全景三维重建方法。首先,利用结构光编码向场景投射正弦模板生成像素级的相位码字以丰富场景特征,进而在多个角度独立地进行光场采集。然后,在各个光场采样视点的内部利用空间信息和角度信息求取深度值。最后,在不同的光场采样点之间由位姿引导实现三维信息融合。实验结果表明,所提方法能有效恢复物体的全景信息,而且对物体纹理特征匮乏区域的重建也更加准确。
关键词:图像处理;三维重建;光场;结构光;相位编码;点云
1引言
三维重建是计算机视觉中的一项重要任务,广泛应用于虚拟现实技术[1]、无人驾驶[2]、机器人视觉导航[3]等领域。基于多视图匹配的三维重建技术如structurefrommotion(SFM)[4]和simultaneouslocalizationandmapping(SLAM)[5]已经被用于大规模场景的稀疏重建。此类方法通过特征点匹配计算特征点的空间坐标,进而重建出物体的三维模型。然而它们面临着两方面不足:1)场景中的特征点分布稀疏,导致重建的三维模型也十分稀疏,无法描述几何细节;2)特征点的匹配计算复杂,制约三维重建的速度。
四维光场(LF)[6]同时记录光线的强度和方向,其数据高维度的优点催生了大量应用;并且随着Lytro和Raytrix等便携式光场摄像机的普及,基于光场的三维重建方法被陆续提出。光场根据数字重聚焦中的最佳剪切值[7]或极平面图像(EPI)中的最优斜率[8-9]来获取场景深度。Tao等[10]综合度量散焦线索和相关性线索两种代价获取深度值。Williem等[11]综合度量约束角熵代价和约束自适应离焦代价获取深度值。Peng等[12]认为在同一视点不同视图中的深度图包含互补信息,并提出融合不同视图实现目标重建的方法。此类方法通过精确的深度值估计实现物体重建,但深度线索依赖光场的空间和角度信息,只能在单一视角重建目标,无法恢复目标完整的全景三维信息。
全景三维重建需要从不同的视角获得场景的几何信息再进行融合,常见的方法有360°重建和720°重建。360°重建中,视点沿水平环形布置,720°重建则同时沿着水平和垂直方向环形布局。这一类方法利用场景几何与光场结构之间的关系计算位姿[13]或者利用高精度的采集设备获取位姿[14],并由位姿引导实现立体匹配。Chen等[15]使用双边一致性度量进行可靠的光场立体匹配。Zhang等[16]在此基础上提出P-SFM,结合立体匹配技术和光场光束平差技术计算光场相机位姿和场景几何形状。Vianello等[14]利用高精度采集设备获取360°环形光场,利用Hough变换计算环形EPI获取单视点深度并使用采样过程中得到的位姿实现信息融合。宋征玺等[17]在此基础上构建三维霍夫空间提取空间点轨迹实现重建。此类方法可以实现物体的全景三维重建,然而深度计算和位姿估计均依赖于表面纹理,可靠性相对较差。因此通常需要较多的数据,利用数据冗余来提高三维重建的可靠性。
针对以上问题,本文提出一种基于多视点编码光场融合的全景三维重建方法。使用光场相机环绕物体进行采样,利用光场内部的高维数据独立获取各个视点的深度值,进而将不同视点的深度值转换为点云并在全局坐标空间中融合,实现物体的全景重建。同时,在普通光场的基础上引入相位编码光场以丰富场景特征,从而提高深度值质量。所提方法具有以下优点:1)采用编码光场的相位编码代替自然场景,解决弱纹理或无纹理区域由于缺乏特征导致的深度估计不准确问题。2)采用多视点融合策略,解决普通光场只能实现单视角重建的问题,实现全景重建。同时在采样过程中获取单视点精确位姿,消除位姿计算导致的视点间匹配不准确问题。3)采用沿水平和垂直方向进行环形布局的信息采集方法,在获取物体全景信息的同时减少视点采集数。
2多视点三维重建算法
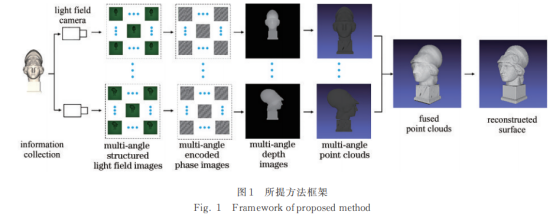
所提基于多视点编码光场的精确三维全景重建方法的总体框架如图1(a)所示,采用结构光编码技术赋予场景像素级码字特征,使用光场相机获取不同视点的编码光场,然后独立计算不同视点的深度值,最后将不同视点的信息在三维坐标空间中融合。相对于已有的三维重建方案,所提框架具有以下特点:1)在深度值估计阶段,采用一种符合结构光特性的重聚焦方法,在提高深度值精度的同时降低复杂度;2)在视点融合阶段,使用采样中的位姿进行点云融合,避免重新计算位姿引起的误差;3)提出一种基于统计的飞行像素去除方法,优化重建目标在深度不连续区域的精度。
2.1相位编码光场的获取
在各个视点采用相位编码光场进行深度值估计,采用多步相移法进行像素级编码,在减小量化误差的同时产生准确连续的码字。具体来说,使用N张同时受水平和垂直坐标调制的正弦函数模板,其中,第i张模板被定义为
![]()
式中:A表示振幅;(s,t)表示像素的坐标;T表示正弦函数周期。这些图像由光场相机采集,通过N步相移法获得包裹相位:
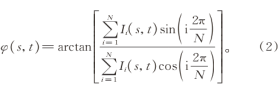
包裹相位φ(x,y)通过arctan函数求出,相位值分布在(-π,π)中,并在水平和竖直方向上周期性循环。通过多步相移法得到的图像,像素值在其邻域内连续且唯一。
2.2改进的重聚焦算法
通过第2.1节得到编码光场后,使用重聚焦算法进行深度估计。对于编码光场,通过四维剪切对其进行重聚焦
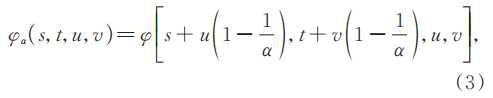
式中:φ表示光场图像;α表示剪切值;φα表示重聚焦之后的光场图像;(u,v)和(s,t)表示角度坐标与空间坐标。当重聚焦图像聚焦于一个特定深度值时,聚焦平面上的点所处角块的强度一致,成像最为清晰;而聚焦平面以外的散焦点则变得模糊。剪切值α反映场景的深度值,通过代价函数Cost(φα)评估深度线索,代价最小的α对应最佳深度值。
![]()
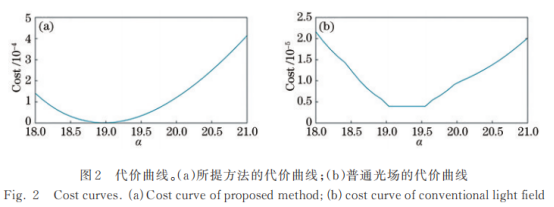
传统光场的代价曲线如图2(b)所示,受均匀纹理、复杂光照和遮挡等因素影响,场景的强度值相似或相同,代价函数出现多个最小值使α无法唯一地收敛,导致深度值估计不准确。针对上述问题,对传统重聚焦算法在光场采集和代价计算两方面进行改进,充分利用编码光场特性,在减小计算量的同时提升深度估计的精度。
在光场重采样阶段,传统数字重聚焦的精度受光场低分辨率的制约,采样像素在多个的剪切值下均保持相同。当剪切值为α0和α1时,最邻近的采样像素均为(s0,t1),产生量化误差降低视差的精度,如图3(a)所示。为解决这个问题,采用双线性插值法重新计算亚像素相位值,如图3(b)所示,将剪切值α采样下的亚像素相位值记为
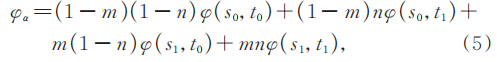
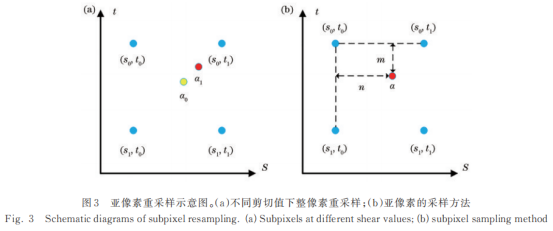
式中:φα(s,t)表示空间坐标(s,t)处的相位值;n和m为亚像素与其左上方整像素点间的水平和垂直距离。普通光场使用强度作为编码信息,像素间不具有连续性,使用插值法破坏了图像的空间结构;编码光场的像素在水平和垂直方向均连续,基于双线性插值的亚像素采样方法充分利用这一特性,在不破坏光场空间结构的同时提升数字重聚焦的采样精度。
得到重采样的相位后,数字重聚焦通过代价最小化计算深度值。Tao等[10]将散焦线索和相关性线索作为代价计算场景深度。当α重新聚焦到正确的深度时,相关性线索要求光场图像中所有与(s,t)对应的像素构成一个具有最小方差的角块,同时散焦线索要求该角块的像素值与中心视图相应的像素值的差异最小。根据Cai等[18]的研究,相位编码光场对散焦线索不敏感而对相关性线索敏感。因此仅使用相关性线索定义代价函数:
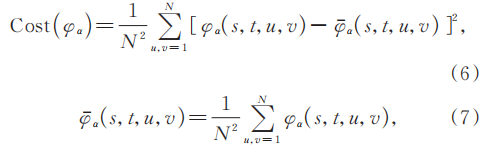
式中:N表示光场的角度分辨率;φα(s,t,u,v)表示剪切值α下采样像素的相位值。仅使用相关性线索定义代价函数,在保持光场深度估计准确性的同时减小了运算量,加快了运算速度,如式(4)所示,通过计算求取最小化代价Cost(φα)的剪切值α,进一步通过文献[10]中的方法即可得到场景的深度值。
2.3多视点三维信息融合
为实现物体全景三维重建,在相位编码重聚焦求得单视点深度图的基础上,还需要融合多视点的三维信息。对测量目标在多个水平和垂直的视点进行采样得到不同视点信息,使用数字重聚焦计算各视点的深度图,将各视点深度图中的像素投射到三维坐标空间,并使用位姿匹配实现信息融合。
对于任意一张深度图,通过下式将像素(s,t)转换为空间坐标(x,y,z)进而转换为点云:
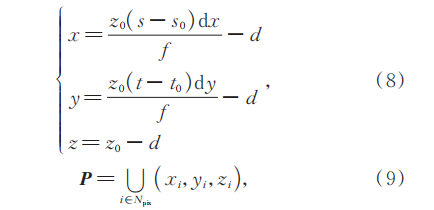
式中:z0表示像素(s,t)处的深度值;f表示相机的焦距;d表示焦点与旋转中心的距离;(s0,t0)表示深度图中心像素的坐标;dx和dy表示单一像素点在水平和竖直方向上的物理尺寸;P表示单视点的点云;∪表示空间坐标的集合;Npix表示深度图像素个数。
图4(a)中,将物体首次采样的视点作为参考系,沿水平和垂直两个方向进行采样。将采样过程中水平和垂直方向的旋转角度定义为θ1、θ2,则水平和垂直视点的位姿为
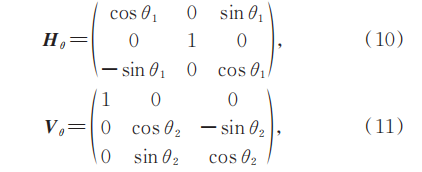
式中:Hθ表示水平视点的位姿;Vθ表示垂直视点的位姿。
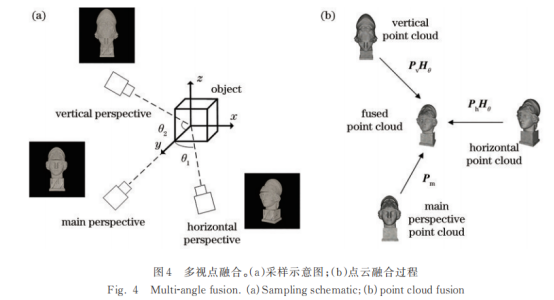
在实际应用中,由于光场相机的旋转角度θ1难以测量,通常固定光场相机并使用步进电机控制的高精度旋转台对物体进行指定角度的旋转[17]实现水平视点采集。由于水平方向进行360°采集已经覆盖了目标的大部分区域,垂直方向的视点只需覆盖顶部和底部,即θ2为90°和270°两个特殊视点即可。
在获得不同视角点云位姿后,通过下式将多视点的点云融合,如图4(b)所示:
![]()
式中:Pv表示垂直视点的点云;Ph表示水平视点的点云;Pm表示主视点的点云;∪表示单视点下点云的集合;P表示融合后的点云。
在多视点点云融合过程中,不同视点的点云存在重叠部分,如图5(a)所示。这些点被视为物体表面的重复采样点,使点云重叠区域的密度大于单视点点云密度,给物体重建带来了误差。使用一种基于体素的重复点云处理方法来解决此问题,如图5(b)所示,对于源点云,建立其对应的八叉树,并将目标点云和源点云中存在于同一体素的点定义为重叠点。此时两个点云的重复点在同一体素中,使用体素下采样或者Laplace平滑[19]均可有效融合重复点云。处理后的点云,重叠区域和不重叠区域的密度保持一致,提升了重建物体的质量。
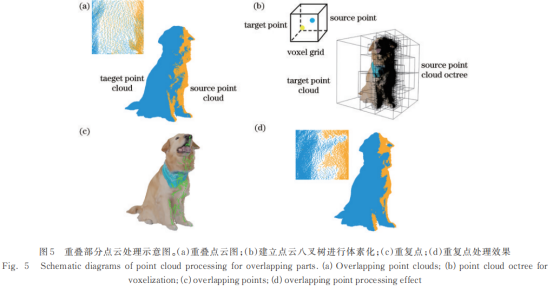
2.4飞行像素移除
为进一步提升三维重建质量,提高点云在深度不连续区域的精度,提出一种基于统计式的离群点移除策略消除飞行像素。飞行像素的产生原理如图6(a)所示,像素p3同时记录来自多条路径的光,当像素看到前景物体的边缘和非遮挡的背景物体时,采集的强度/颜色将是前景和背景强度/颜色的混合。飞行像素被视为错误的采样点,从而带来了误差。
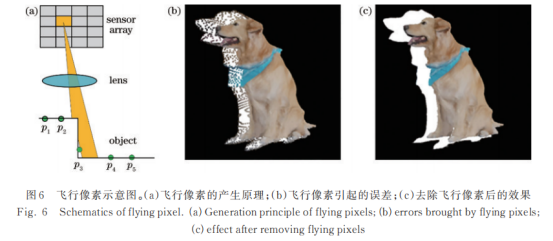
飞行像素的强度是前景和背景的加权和,将深度图转换为点云后,飞行像素点与其他点的距离往往更远。利用这一特性,提出一种统计式离群点移除策略,这些点满足
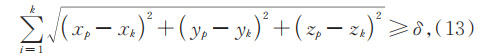
式中:(xp,yp,zp)表示为离点p最近k个点的空间坐标;δ为所设的阈值。式(13)可以有效寻找所有与邻域的其他点距离较大的点,通过调整适合的阈值δ索引飞行像素点并移除。具体效果如图6(c)所示,该方法计算量小,且在去除离群点的同时提升了物体的边缘质量。
3.实验结果与分析
3.1实验设置
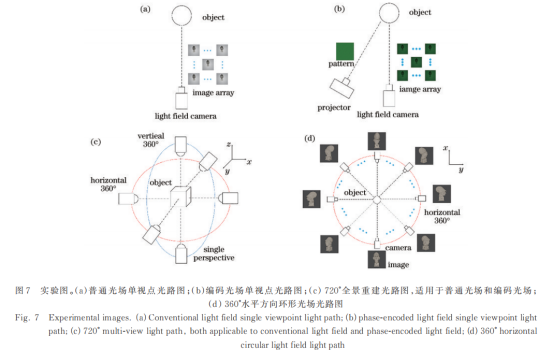
将所提算法与3种三维重建算法进行对比,分别为普通光场三维重建[10]、clusteringviewsformulti-viewstereo(CMVS)[20]、multi-viewstereo(MVS)[21]。相应地,构建了3种数据,具体的测试方法和对应的实验数据如表1所示。1)针对CMVS和MVS,构建水平360°环形光场,如图7(d)所示,相机环绕旋转轴1°等间隔均匀采样以获取场景的360°信息,一个数据集包含360张普通纹理图像。2)针对纹理光场的三维重建[10],构建720°普通光场,如图7(c)所示,该数据包含6个视点,在水平和垂直方向分别构成360°环形采集,每个视点为图7(a)所示的普通光场采集的纹理信息。光场相机焦距为43.456mm,每个视点包含7×7共49张图像,整个数据集包含294张视图。3)针对所提编码光场的三维重建,构建720°编码光场,其采样方式仍如图7(c)所示,但各视点为图7(b)所示的编码光场[22]。其光场相机参数和普通光场相同,模板使用正弦函数的周期为42,整个数据集包含294张视图。
值得注意的是,CMVS和MVS需要密集的采样视点建立视点间相关性,当视点间距大时无法进行匹配,故使用图7(c)所示的采样方法无法得到重建结果。根据Vianello等[14]和宋征玺等[17]的研究,使用图7(d)所示的环形光场并采用1°间隔采样时可取得可接受的重建效果,此时需360张采样图像,已经高于普通光场和编码光场294张视图的数据量。为在尽可能接近的数据规模上比较性能,对环形光场仅进行水平360°重建。

3.2与现有方法的精度比较
从表1可以看出,采用4种方法在3组数据集上测试重建效果及生成mesh的误差,结果如图8~10所示,其中,误差图颜色越深代表误差越大。MVS和CMVS在环形光场数据集的实验结果如图8~10(a)、(b)所示,可见MVS重建结果在边缘处具有较多噪声,而CMVS重建点云密度较稀疏。使用泊松表面重建[23]将点云重建为网格后,所得到的重建结果误差较大。同时,使用环形光场数据集进行三维重建会丢失顶部和底部信息,只能完成水平360°重建。传统光场三维重建方法和所提方法的测试结果如图8~10(c)、(d)所示,结果表明,通过不同视点求取深度值再进行融合,所得重建效果整体优于CMVS和MVS,利用更少的输入图像生成了更精确的三维信息。同时从图8~10(c)可以看出,普通光场数据集难以对弱纹理或无纹理区域进行有效重建,而从图8~10(d)可以看出,使用编码光场可以得到更好的点云,网格的重建结果也更加平滑和准确,实现了精确的全景三维重建。



为更好呈现全景三维重建效果,选取5个随机角度对生成的网格与真实值进行对比,结果如图11所示,所提方法可以获取物体的全景信息并融合,在各个角度均能观测到物体的三维信息。

3.3光场角度分辨率对结果的影响
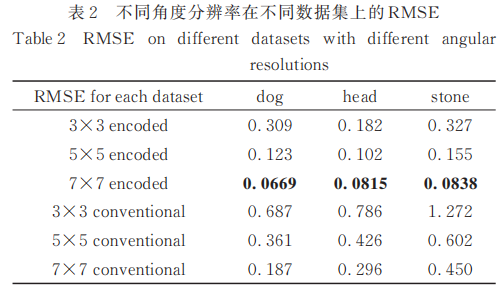
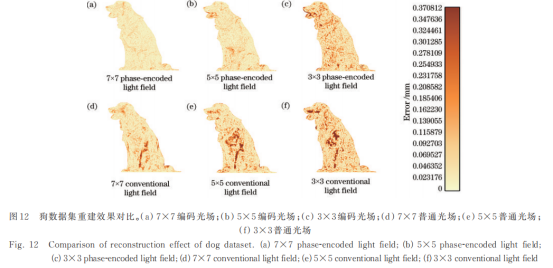
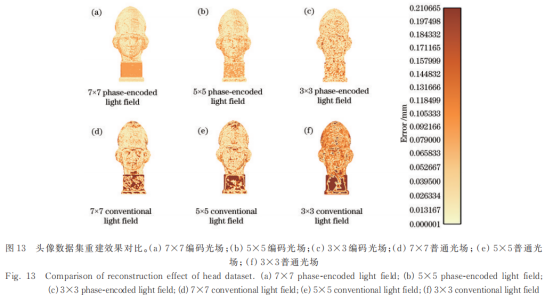
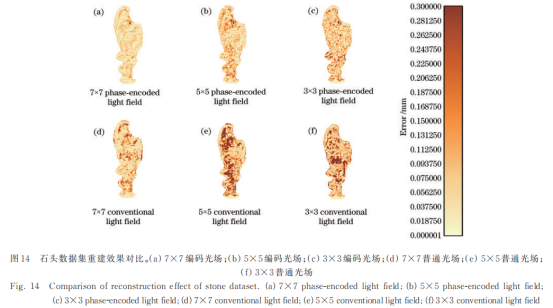
为分析编码光场的角度分辨率对结果的影响,即重建质量随输入数据量的变化,测试角度分辨率为3×3、5×5、7×7的普通光场与编码光场所得点云的均方根误差(RMSE)[24],结果如表2所示。从表2可以看出,随着单视点光场采样角度分辨率的增加,普通光场和编码光场的RMSE不断减小,表明视点数目的增加提供了更强的约束,从而生成更准确的三维信息。同时,在相同角度分辨率的情况下,编码光场得到的点云质量优于普通光场,即光编码提供了更准确的深度线索,生成了更准确的深度值。
除了客观指标,还比较了重建mesh和真实值的误差,结果如图12~14所示。从图中可以看出:输入光场的角度分辨率改变时,普通算法受角度分辨率的影响更大;而所提算法在输入不同尺度的光场情况下,均能得到完整的信息和精确的轮廓。此外,其结果也表明所提算法的mesh质量优于普通算法,重建结果更加准确且平滑,从而验证了其有效性。
3.4重建精度影响因素分析
还探索了具体实施中不同因素对重建精度的影响,主要包括输入图片空间分辨率、旋转角精度及模板的噪声。重建误差以RMSE衡量,结果如表3所示,重建mesh的误差如图15所示。输入图像的空间分辨率影响深度值的精确性,进而影响重建结果,测试并分析了在输入分辨率为512×512、448×448、384×384时的重建效果。随着空间分辨率降低,视差和深度值精度降低,生成点云的误差增大。视点的旋转角θ1和θ2将影响点云的融合,进而降低重建质量,测试并分析了旋转角出现1°~5°误差时的重建效果。随着角度误差的增加,重建结果的误差也迅速增大。模板噪声降低深度值的准确性,降低重建质量,对相位模板加入方差为0.01、0.05、0.1的高斯噪声并测试重建效果。随着噪声增强,重建结果的RMSE略微增加。
4 结论
针对传统光场重建信息不全,在纹理匮乏和重复区域重建结果不精确等问题,提出一种基于多视点的编码光场三维重建的方法。通过相位解码、深度估计、多视点融合、飞行像素去除等一系列步骤进行优化,实现了物体的精确全景重建。实验结果表明,与现有方法相比,该方法可以在更少的输入情况下得到更加精确的重建结果,同时其在弱纹理或无纹理处重建的结果更加平滑。同时,还分析了角度分辨率、空间分辨率、模板噪声等因素对重建质量的影响。
文章来源:激光与光电子学进展 第60卷第12期
文章作者:王泽宇,向森,邓慧萍,吴谨
相关链接:http://www.opticsjournal.net/Articles/OJ46b4470ef4ff0194/Abstract
声明:转载此文目的在于传递更多信息,仅供读者学习、交流之目的。文章版权归原作者所有,如有侵权,请联系删除。